
- Stable Diffusionの使い方【基本】
- モデルをダウンロードして追加する【Stable Diffusion checkpoint】
- 生成画像のクオリティを上げる1【Sampling method】
- 生成画像のクオリティを上げる2【Sampling steps】
- 画像のサイズを変更する【Width/Height】
- 連続生成数を増やす【Batch count/Batch size】
- プロンプト(呪文)がきかない【CFG Scale】
- 同じ顔、同じキャラを生成したい【seed】
- 画像や写真からイラストを生成【img2imgの使い方】
- 画像の一部を修正する【inpaintの使い方】
- Stable Diffusion Web UIの使い方 終わり
Stable Diffusionの使い方【基本】
Stable Diffusion Web UI の使い方を初心者向けに解説します。Stable Diffusion Web UI のインストールがまだのかたは、Stable Diffusionのダウンロード/インストール方法(日本語化つき)のほうを先に見てください。
テキストから画像を生成する①
「txt2img」タグの上のボックスに生成したい画像のテキストを入力し、右のオレンジボタン「Generate」を押すことで右下に画像を生成することができます。ここで入力するテキストのことを呪文、またはプロンプトと呼びます。
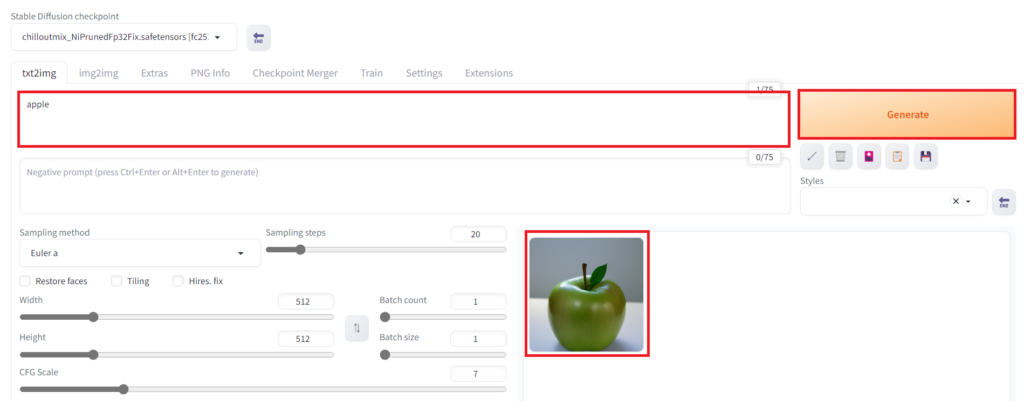
テキストから画像を生成する②
除外したい要素がある場合は先ほどのボックスの下のボックスにテキストを入力します。例では犬を生成したいのですが、白や黒の犬は生成してほしいけど、茶色の犬を生成してほしくなかったので茶色を除外要素に入れて生成したものです。この除外したい要素のテキストのことをネガティブプロンプトと呼びます。
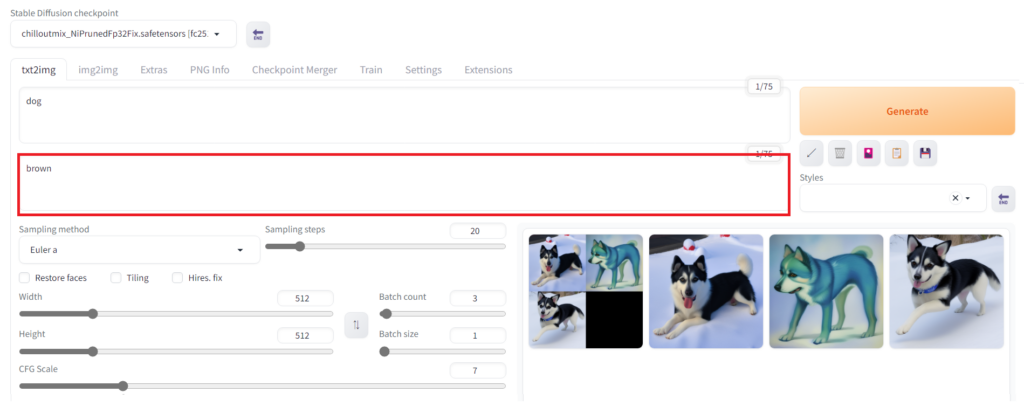
モデルをダウンロードして追加する【Stable Diffusion checkpoint】
モデルとはイラストの絵柄のことです。モデルを切り替えることでリアル調のイラストやアニメ調のイラストなど好みの絵柄で画像を生成することができます。


モデルのダウンロードとインストール
モデルは配布されている外部サイトでダウンロードすることで入手できます。例えばリアル系で最もメジャーなモデルは以下のサイトで配布されています。
ChilloutMix – Chilloutmix-Ni-pruned-fp32-fix | Stable Diffusion Checkpoint | Civitai
他のモデルが使いたい、おすすめのモデルが知りたい場合は、Stable Diffusion モデル/おすすめ【リアル系/アニメ系】をご確認ください。
リンクをクリックして、サインインをしたら、青いボタンの「Download」をクリックします。
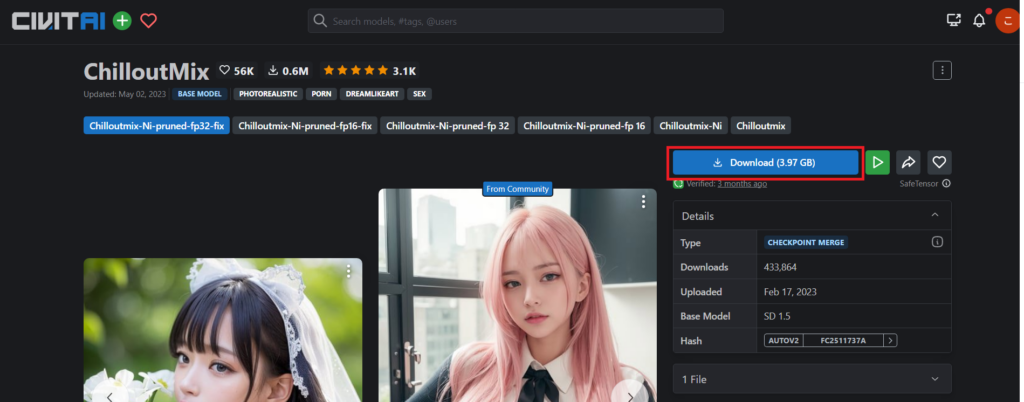
ダウンロードしたファイルをStable Diffusion をダウンロードしたフォルダ
stable-diffusion-webui\models\Stable-diffusionに配置します。
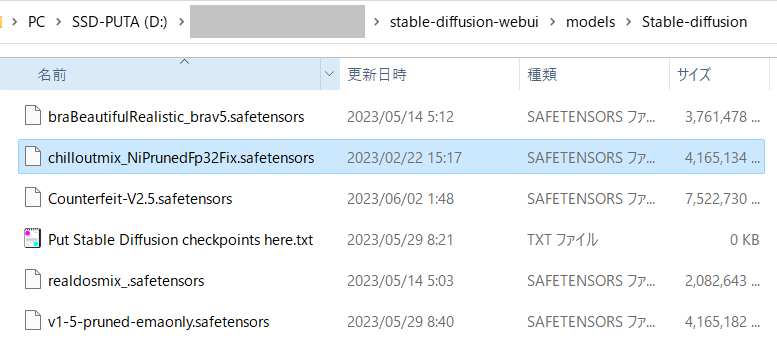
Stable Diffusion Web UI の一番上にある「←END」ボタンをクリックします。そうすると左の「Stable Diffusion checkpoint」で今ダウンロードしたモデルが選択できるようになるので選択します。
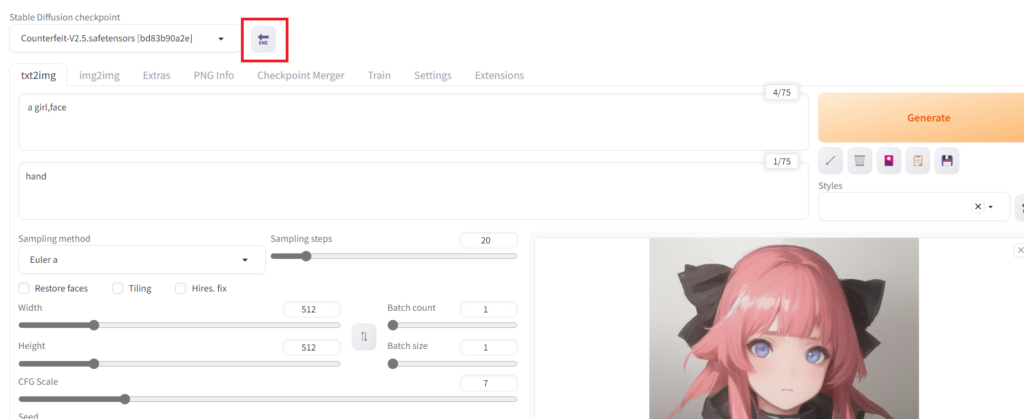
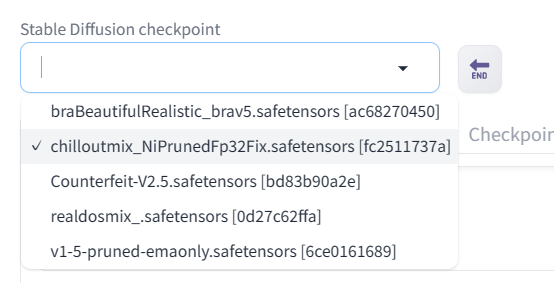
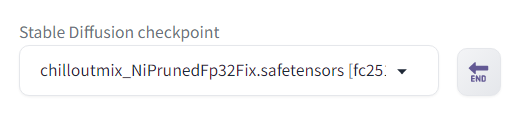
これでモデルのダウンロードとインストールは完了です。
おすすめのモデル
リアル系モデルは、上のモデルのダウンロードの時に紹介したこのモデルになります。
ChilloutMix – Chilloutmix-Ni-pruned-fp32-fix | Stable Diffusion Checkpoint | Civitai
アニメ系のモデルは、以下のサイトのものがおすすめです。「Counterfeit-V2.5.safetensors」(バージョンは適宜最新のものを選んでください)の右側にある「↓」を押してダウンロード可能です。
gsdf/Counterfeit-V2.5 at main (huggingface.co)
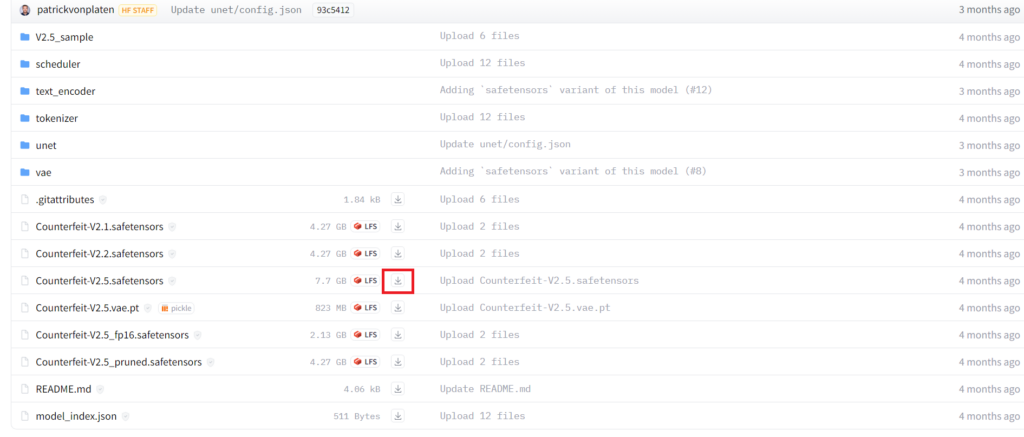
その他おすすめのモデルはStable Diffusion モデル/おすすめ【リアル系/アニメ系】こちらをご覧ください。
生成画像のクオリティを上げる1【Sampling method】
Stable Diffusion Web UIにはサンプラーというものがあり、画像の生成時間やイラストの質を変化させる機能があります。下記画像の赤字の部分(Sampling method)を変更することでサンプラーを変更することができます。
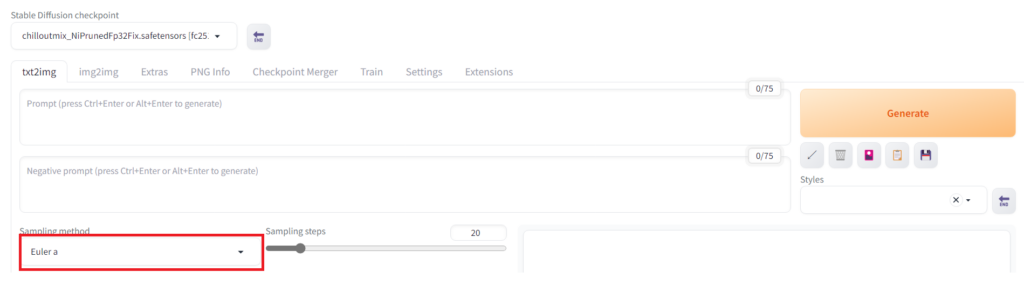
おすすめのサンプラー
サンプラーは各モデルが推奨しているものを選ぶのがよいです。モデルが推奨しているものがなければ、生成画像の好みで選んでもよいですが、以下のサンプラーがおすすめです。
- Euler a
- DDIM
- DPM++ 2M Karras
生成画像のクオリティを上げる2【Sampling steps】
Sampling stepsの数値を上げると、画像の生成に時間がかかるようになる代わりに、画像のクオリティを上げることができます。サンプラーよりもこちらのSampling stepsのほうが重要度は高いです。
アニメ系モデルでは20前後で複数枚生成し上手くいかないようであれば、Sampling stepsを上げてみることで良いイラストが生まれることがあります。リアル系モデルでは20前後では微妙なイラストができやすいため初めから60前後で始めたほうが良いです。
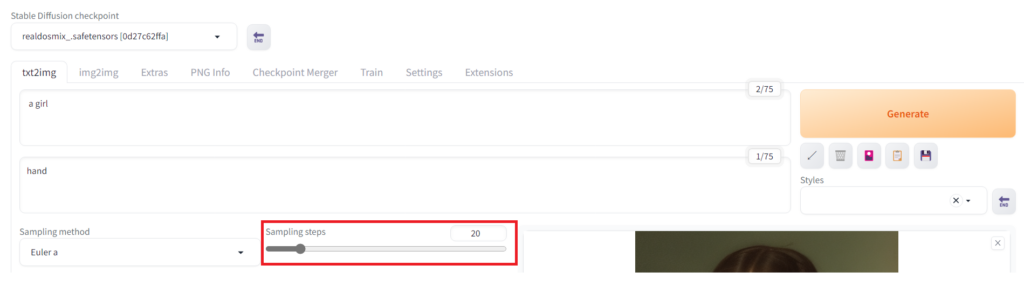


画像のサイズを変更する【Width/Height】
生成する画像のサイズを変更するには「Width」と「Height」の値を調整します。
連続生成数を増やす【Batch count/Batch size】
生成数を増やすには「Batch count」と「Batch size」を変更します。
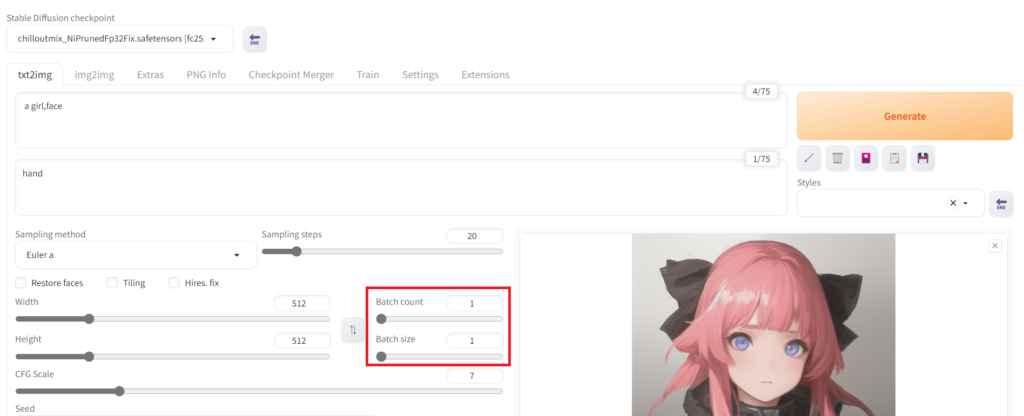
「Batch count」は単純に生成回数のことです。2にすれば2回生成されます。
「Batch size」は1回の生成時の生成枚数です。同じように2にすれば画像は2枚生成されますが、1回あたりの生成に時間がかかるようになります。
「Batch count」は徐々に1枚ずつイラストができるのをを眺めることができるのに対し、「Batch size」は全部生成されてから一気にイラストが出力されるので好みに合わせて使い分けてください。
プロンプト(呪文)がきかない【CFG Scale】
プロンプト(呪文)通りにイラストが生成されない場合は、「CFG Scale」を変更します。
数値を大きくすればするほど、プロンプトを無視した出力が減り、呪文に従ってくれるようになりますが、AIが自分で考えて命令されていないことを補えなくなるため、色や構図がおかしくなっていきます。基本は元の「7」から変更しないのが無難です。
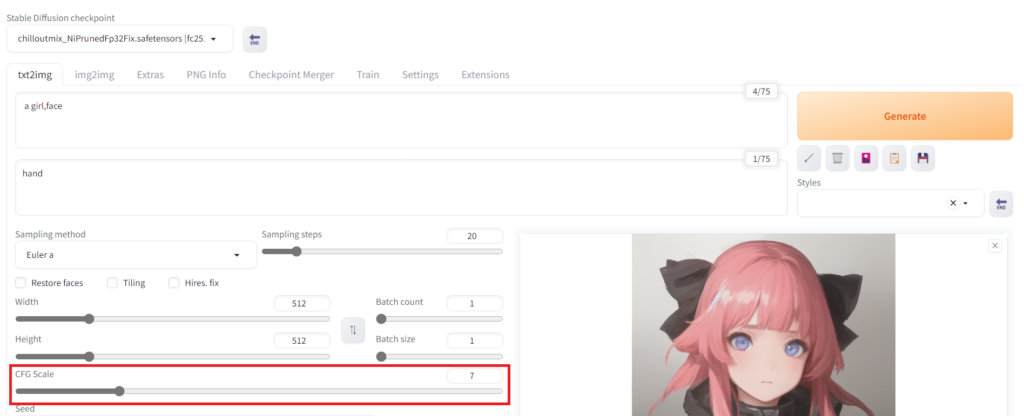
同じ顔、同じキャラを生成したい【seed】
一度生成したキャラクターと同じ顔のキャラクターを生成したい場合は「seed」の値を変更します。このシートはデフォルトの「-1」状態ではランダムなseed値が毎回設定されるため、毎回別のキャラクターが生成されます。「seed」の右側のサイコロマークを押すと「-1」が設定されます。
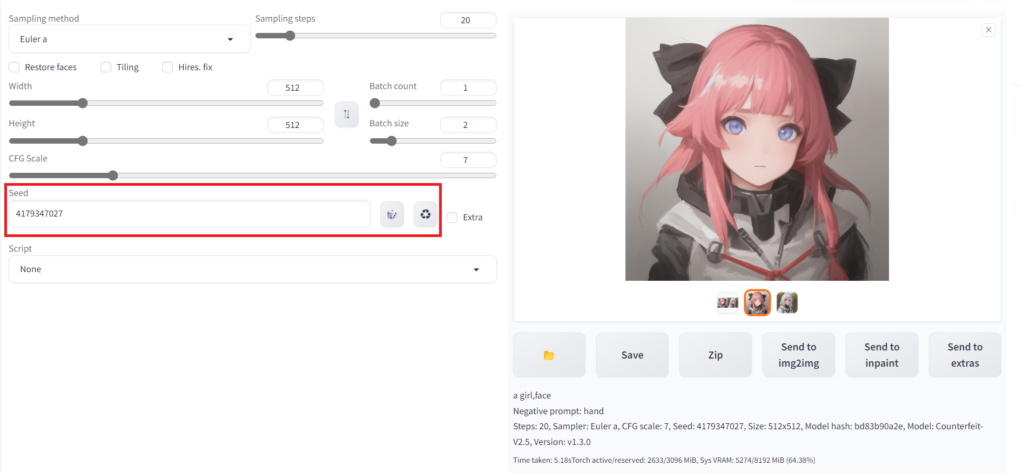
「seed」の右側のサイコロマークの右のマークをクリックすると今選んでいる画像のシード値がSeedに設定されます。この状態でプロンプトを変えると同じキャラクターで別の構図のイラストができやすくなります。


画像や写真からイラストを生成【img2imgの使い方】
img2imgという機能を使ってペイントで書いた画像を女の子にしてもらいました。このように画像や写真を使ってAIイラストを生成することが可能です。


使い方は「img2img」タブを開きます。タブのすぐ真下に画像をアップロードしてあとは通常のテキストでの画像出力と同じように呪文や画像サイズなどを生成し「Generate」ボタンを押すだけです。
この「img2img」で一番重要なのが、下のほうにある「Denoising strength(ノイズ除去強度)」という設定値でデフォルトは「0.75」です。この数値が高いほど元の画像を無視してAIが考えた絵が生まれ、この数値が低いほど元の画像を意識した絵が生まれます。元の絵がいい場合は、少しだけ変えたい値「0.4」あたりまで下げるとよい絵が生まれるのでおすすめです。
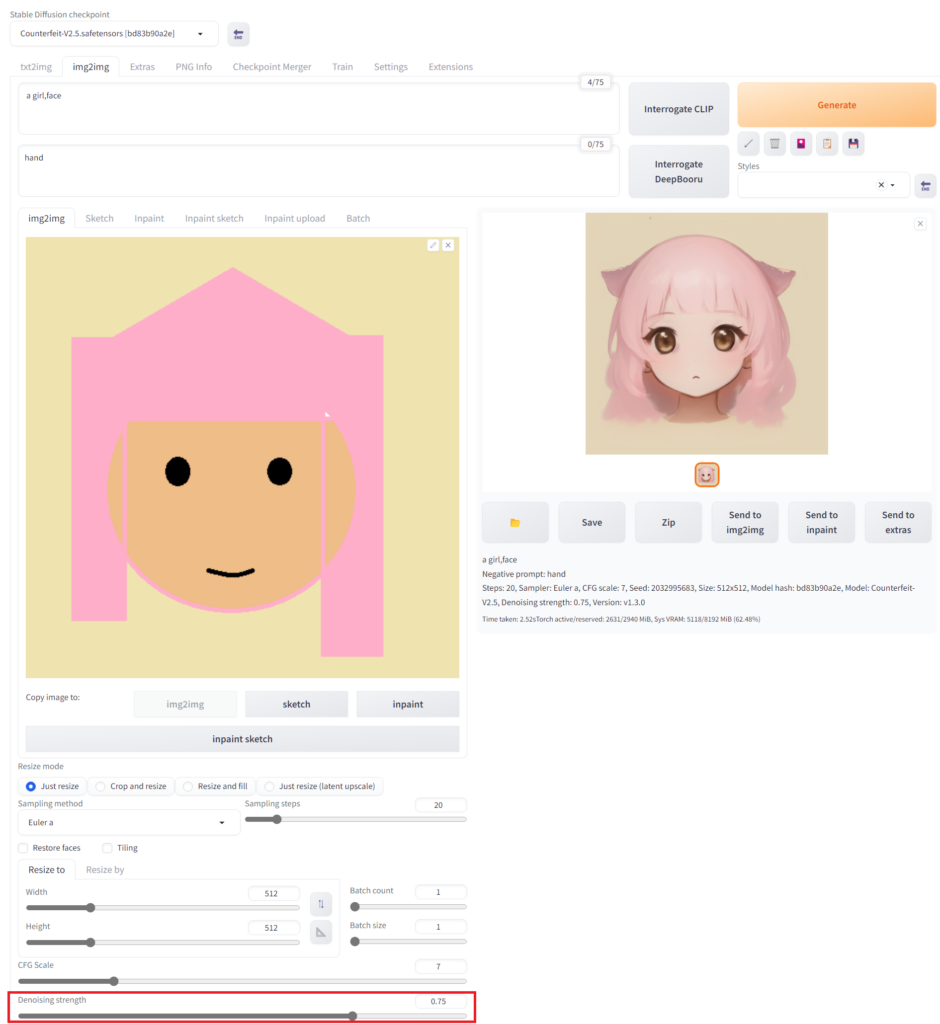
元の絵がひどい場合は、「Denoising strength」の値を下げるのはおすすめしません。

画像の一部を修正する【inpaintの使い方】
AIイラストは手や指の生成が苦手です。せっかく良い絵が生まれたのに一部分だけおかしくて使えないという場合には、inpaintを使ってイラストの一部を修正することが可能です。この機能を使えば手や指を修正できるのはもちろん、表情や色を変えたりすることができます。

使い方は「img2img」タブを開きます。そして下にもタブがあるのでそこで「inpaint」タブを開きます。タブのすぐ真下に画像をアップロードしてイラストの変更したい部分をブラウザ上で直接塗りつぶします。あとは通常のテキストでの画像出力と同じように呪文や画像サイズなどを生成し「Generate」ボタンを押すだけです。※塗りつぶしの枠の右上に小さくてわかりにくいですが、塗りつぶしのペンの太さを変えたり、やり直したりできるボタンもあります。
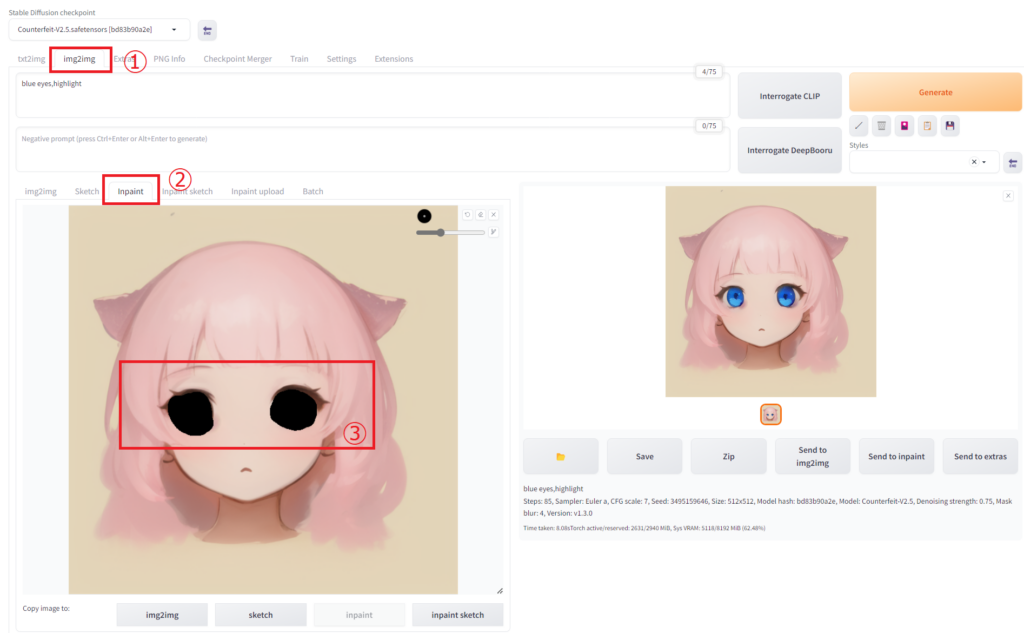
「inpaint」でもで一番重要なのが、下のほうにある「Denoising strength(ノイズ除去強度)」という設定値でデフォルトは「0.75」です。この数値が高いほど元の画像を無視してAIが考えた絵が生まれ、この数値が低いほど元の画像を意識した絵が生まれます。
今回の修正では「Denoising strength」を「0.5」、呪文を「blue eyes,highlight」にして修正しています。
Stable Diffusion Web UIの使い方 終わり
以上が、初心者向けのStable Diffusion Web UIの使い方でした。
当サイトはインターネット上で稼ぐ方法について解説しているサイトです。作ったAI画像で稼ぐにはAIイラストで稼ぐ、収益化の方法にて解説しています。

